理解正则表达式
描述一类字符串的特征,通过这个特征与特定的配合使用,对于其他的字符串进行匹配,查找,替换,分割操作!
了解一些基本概念:这类字符串的特征是由一个或多个
1.普通字符(例如a到z)
2.元字符(有特殊特殊功能的字符,比如*,+,?等),组成一个字符串!
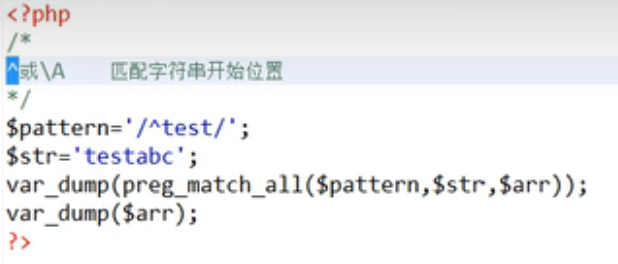
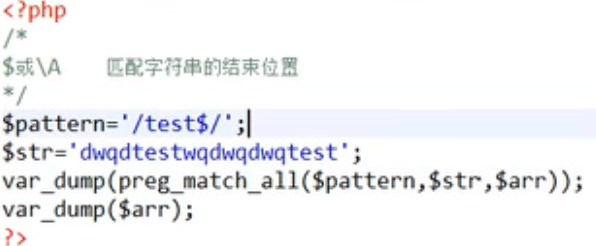
例如‘/a/’,a就是普通字符,/是定界符(表示正则表达式的开始或结束)
preg_match_all
按指定的正则表达式,在给定的字符串进行搜索,匹配到符合特征的部分取出
1 |
|
这里是引用我们一般习惯使用正斜线“/”作为定界的字符,当然除了字母,数字,和反斜线(相当于转译,例如 \’ ->’ )以外的字符都可以作为定界符比如:#,!,(),| 都是可以的!
定界符放在正则表达式的起始位置,前后一致!
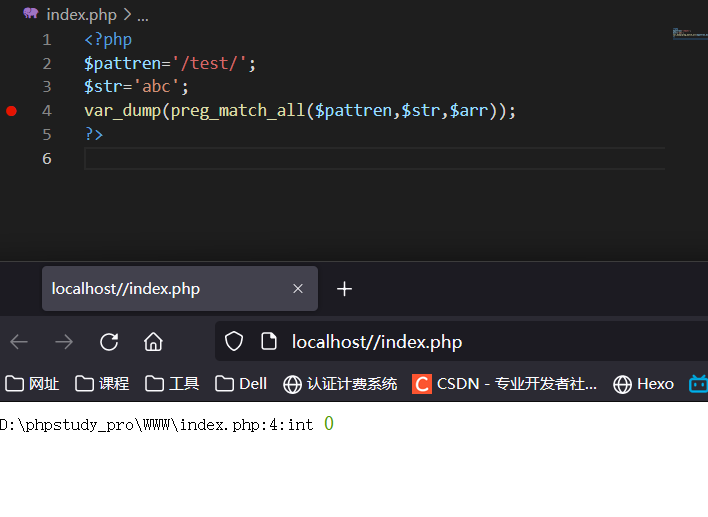
由图可见,没有符合此特征的!http://localhost//文件名本地开开可进行搜索,比较麻烦。自行配置更方便
1 |
|
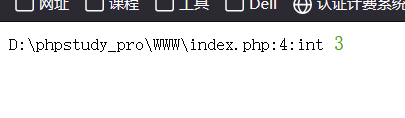

preg_match
在第一次匹配过程中将会停止搜索
参数说明:
第一个参数:正则表达式
第二个参数:目标字符串
第三个参数:放一个变量,执行完成之后,里面会有匹配到的部分以及等等一些数据
第四个参数:可以传PREG_OFFSET_CAPTURE
具体可见PCPE
preg_replace
参考说明:
第一个参数:正则表达式
第二个参数:要替换成的字符串
第三个参数:目标字符串
第四个函数(可选):默认是-1,就是替换所有符合特征部分的
第五个参数(可选):可以放一个变量在这边
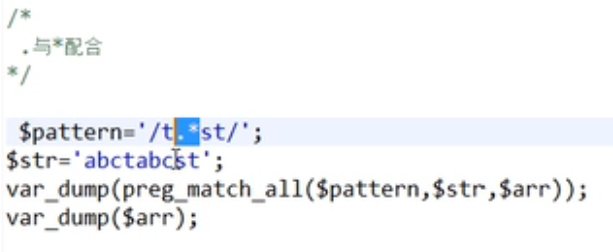
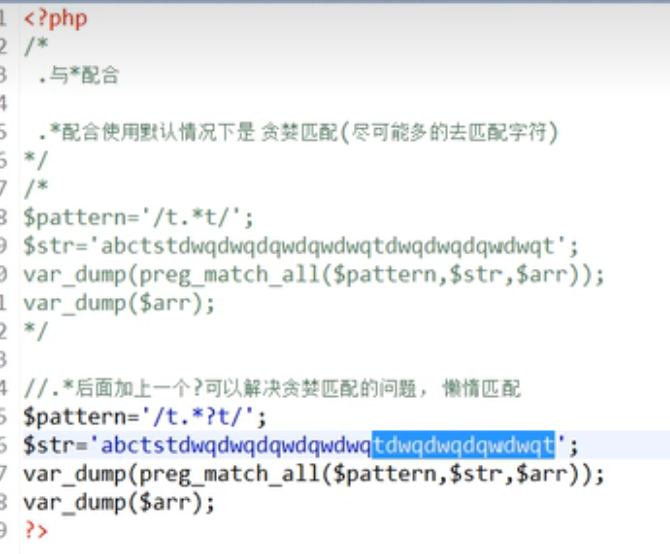
正则表达式元字符
详情可见https://www.runoob.com/regexp/regexp-metachar.html


课程中的配合使用

对于()进行理解
1 |
|

模式修正符
是正则表达式的定界符后使用的,可以调整正则表达式后的解释,扩展正则表达式在匹配,替换等操作时的某些功能,增强正则表达式的处理能力。
修正符m的使用条件:
1.目标字符串必须含\n,在字符串中出现\n就表示新的一行开始
2.正则表达式中必须出现^或者$
(了解一下!\r:回车符,\n换行符)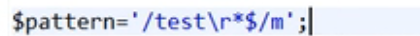
针对Linux系统



